In recent years, the news publishing landscape has undergone significant change, with more publishers turning to subscription models to monetise their content. For those yet to embrace this approach, the question is no longer "if," but "when."
More and more publisher are choosing this type of mentisation:
As of 2024, the leading news publishers by digital-only subscribers are:
- The New York Times: 11 million digital subscribers.
- The Wall Street Journal: 4.25 million digital subscribers.
- The Washington Post: 2.5 million digital subscribers.
- The Telegraph: 1.5 million digital subscribers
- Substack: 2 million paid subscriptions across various newsletters.
Note: These figures are based on the most recent available data and may have changed since their publication.
However, implementing a paywall is far from straightforward. Simply adding a subscription form to a website is rarely enough. Success requires a well-thought-out strategy that carefully considers the interplay between a site’s traffic and how Google will crawl your website.
In this article, I’ll explore the different types of paywalls and their impact on organic traffic.
Types of Paywalls
When it comes to setting up a subscription service, publishers have several options on how to restrict content to their audience. Let’s look at the common ones:
Hard Paywall
A “hard” paywall means that you can’t see any of the content unless you pay first. This might make it tougher to get people to buy because they can’t try it out for free like they can with a “soft” paywall. However, if the content is really special or different in a way that people can’t find anywhere else, they might be willing to pay for it right away.
Example of a hard paywall
The Financial Times (FT) employs a hard paywall model, requiring readers to subscribe before accessing its content. This approach restricts all online material to subscribers, aiming to provide exclusive, high-quality journalism to its paying audience.
Initially, the FT introduced a paywall in 2002 and later adopted a metered model in 2007, allowing limited free article access before prompting for a subscription. However, in 2015, the FT transitioned to a hard paywall, eliminating free article allowances and requiring a subscription for full content access.
Freemium paywall
A Freemium model is when a website (or app) provides some content for free but charges for more detailed or advanced stuff. Publishers who use this approach give you simple articles at no cost, and then if you want more in-depth or special features, you have to pay.
Example of freemium paywall
A notable example of a freemium paywall is employed by The Verge, a technology news website. In December 2024, they introduced a subscription service that maintains free access to their core content—such as news posts, Quick Posts, Storystreams, and live blogs—while placing original reporting, reviews, and features behind a metered paywall. This approach allows readers to access essential content for free, encouraging engagement, while offering premium content to subscribers.
This freemium model effectively balances accessibility with monetisation, providing value to both casual readers and dedicated subscribers.
Metered Paywall (Recommended by Google)
A metered paywall lets you see some content for free for a little while or a few times before you have to pay. Usually, this limit resets every month. Lots of news publishers do this. They might let you read 5 articles for free each month and then ask you to pay if you want to read more. Software companies (SaaS) also use metered paywalls for their subscriptions. For example, your subscription might let you download 20 reports each month. Once you hit that number, you need to pay if you want more.
People often mix up “soft paywall” and “metered paywall,” but they’re not exactly the same. A “soft paywall” typically means there’s a special part of the website with extra good content that you need to pay for, while a “metered paywall” means you can see a certain amount of content before you have to start paying.
Smart Matering Paywall
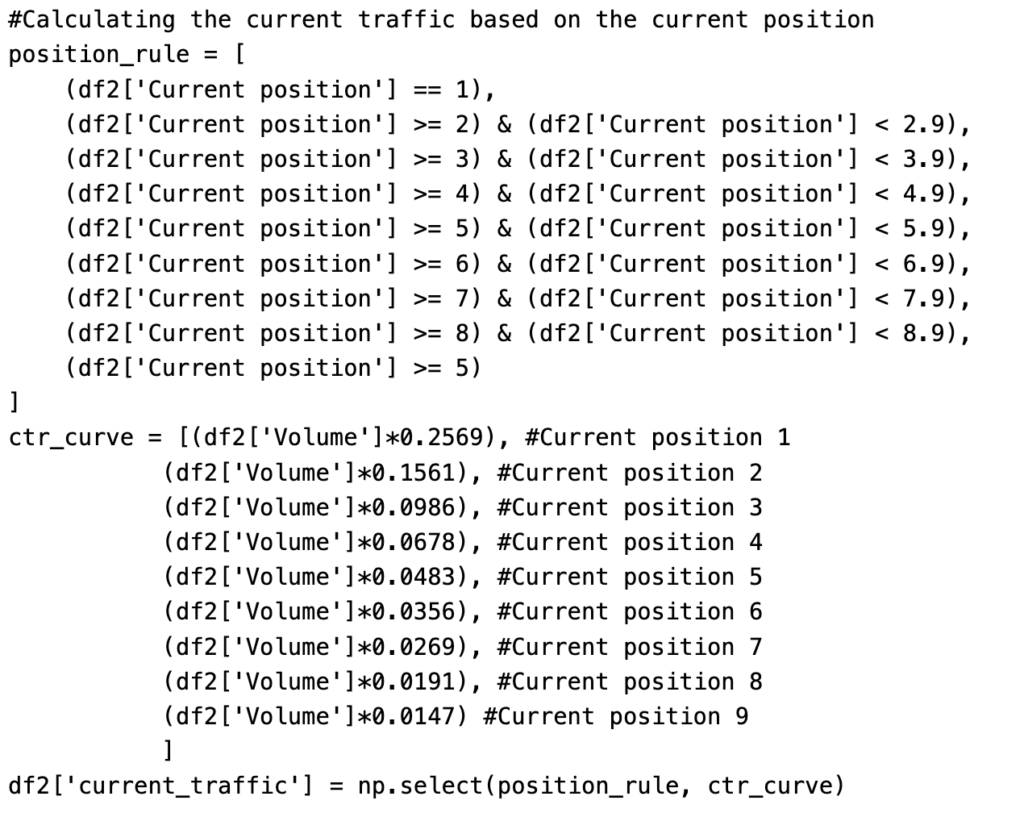
Metering can be seen as a Reinforcement Learning (RL) problem, where an agent learns to take actions in a changing environment to earn the highest total rewards over time. Unlike traditional machine learning, RL adapts to changes caused by the agent’s own actions. It has been used in areas like robotics, gaming, and self-driving cars. In this case, the “metering agent” makes decisions based on the user’s behavior and the content they are trying to access. The agent can choose from three actions, and each choice gets a reward based on how the user reacts. A user’s journey, called an episode, continues until they subscribe or stop accessing content. The goal is for the agent to take the best actions at each step to get the highest overall reward.

If you want to learn more about machine learning, Reinforcement Learning (RL), and how The Washington Post implements paywalls, I recommend reading this article by Janith Weerasinghe on Medium: How the Washington Post Uses Smart Metering to Target Paywalls.
Example of metered paywall
The Washington Post employs a metered paywall model, allowing readers to access a limited number of articles for free each month before requiring a subscription for further content. This strategy enables casual readers to engage with the site while encouraging frequent visitors to subscribe for unlimited access.
In addition to the metered paywall, the Washington Post utilizes a pop-up, anti-scroll feature that prompts users to subscribe after reaching their free article limit. This approach includes form fields and offers various subscription options to cater to different reader preferences.
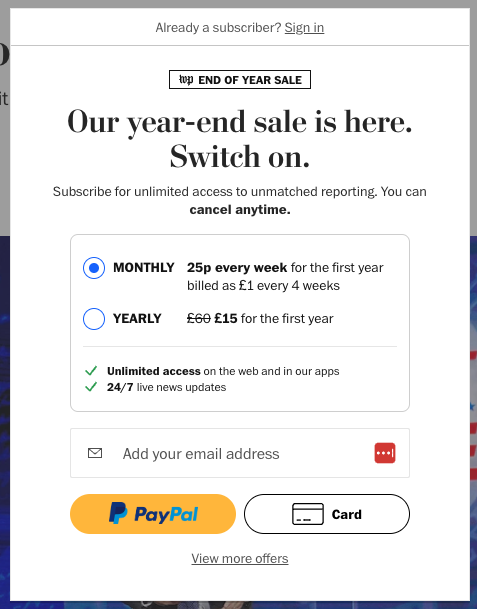
Lead-in (Recommended by Google)
This method is like a strict paywall. You get to see the title and the first bit of the article, maybe the first paragraph or 100 words (it’s up to the published how much will show). It’s a middle ground that lets you check out how good the article might be without giving you the whole thing for free.
Even though this is okay with Google’s rules, it can annoy people who click on the article from a search and then leave right away because they can’t read the whole thing without paying.
Example of lead-in paywall
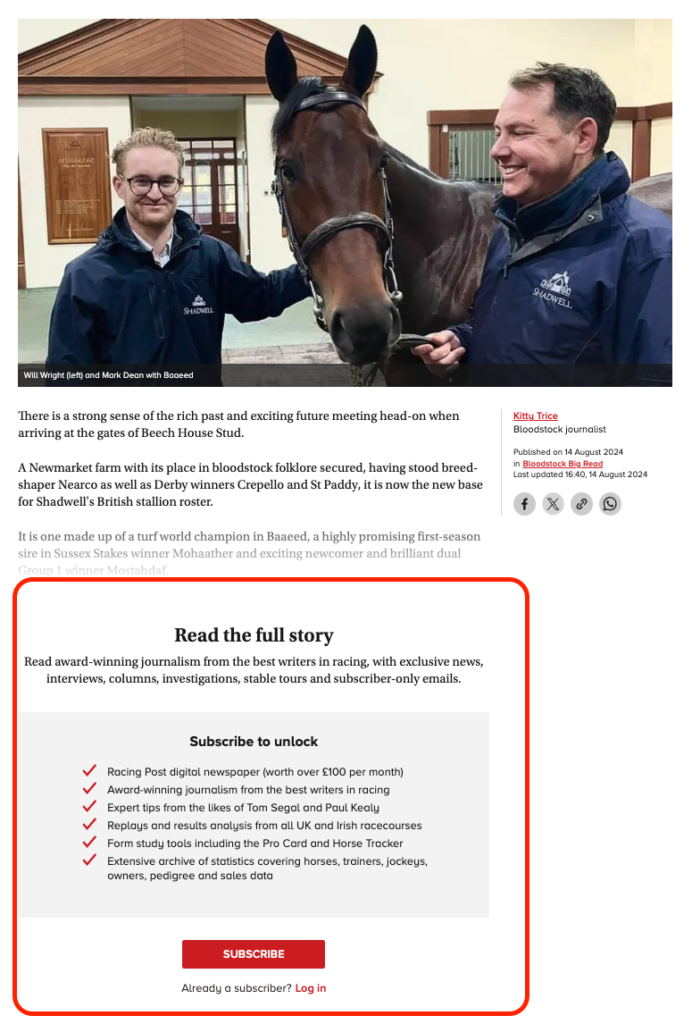
In 2022, I led the technical SEO and website migration for Racing Post as they transitioned from a hard paywall to a lead-in paywall.
Racing Post publishes their tips behind the paywall, and thanks to the flexibility of Next.js, the paywall is rendered server-side. This ensures that users cannot bypass the paywall by disabling JavaScript (JS) in their browsers.
Dynamic Paywall
Dynamic paywalls use what they know about each reader to offer a more personal experience. They look at what you do, what you’re interested in, and how you interact with their content to figure out the best way to get you to subscribe. This is really helpful for news publishers because it lets them see what their readers like best, how often they visit, and even what devices they use.These smart paywalls are all about the reader. They’re not just a one-size-fits-all barrier; they adapt to what you seem to want and need. So, if someone’s really into the content and likely to subscribe, the paywall will notice and adjust the number of free articles they get to see before asking them to pay. This way, it tries to turn more readers into paying subscribers by only asking for a subscription at the perfect time.
Each type of paywall has its own way of balancing reader access with revenue goals, and the choice depends on what fits best with a publisher’s content strategy and their understanding of the audience’s reading habits.
Flexible Sampling and Google
In 2017, Google phased out First Click Free (FCF) and introduced Flexible Sampling as its replacement.
Google doesn’t automatically dislike content that you have to pay to access. It’s fine with this kind of content as long as the website tells Google that it’s behind a paywall.
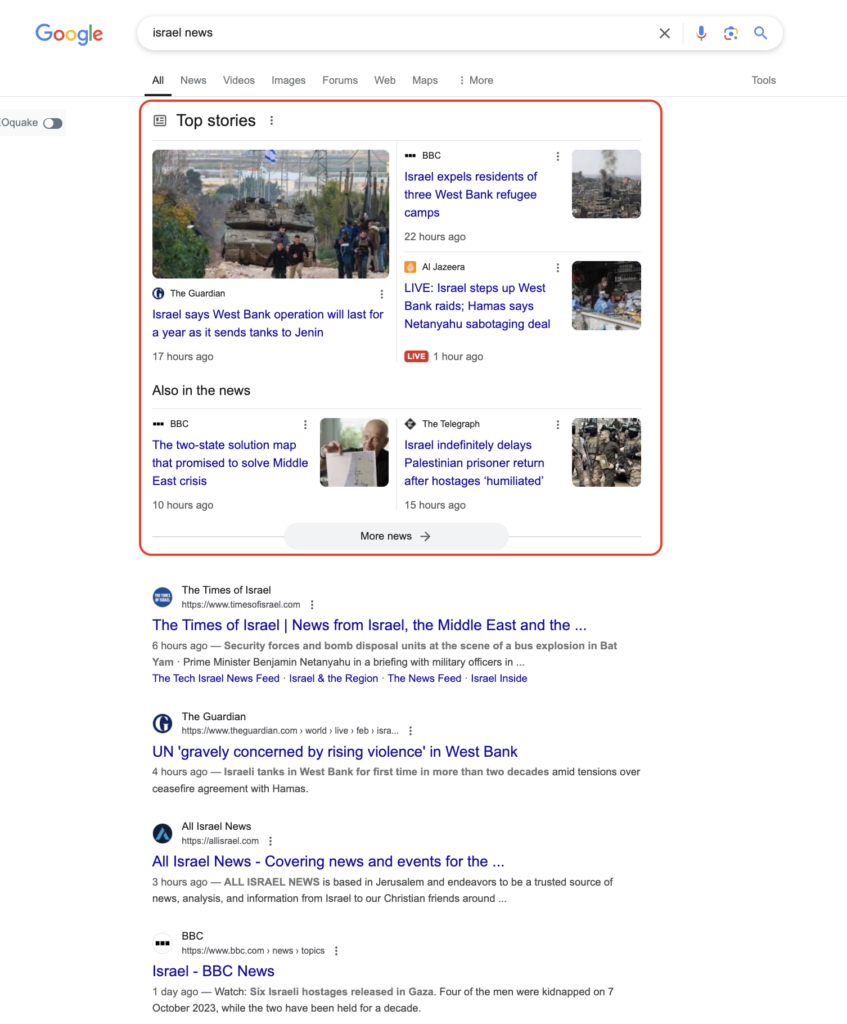
Publishers who use paywalls aren’t left out of Google’s search results. Their content that’s only for subscribers can still show up on various surfaces, like the Top Stories carousel, Aslo News, Google News, Discover, and the regular list of search results.
IMPORTANT: publishers must set up their paywalled content so that Google can look at it. This way, Google can include it in search results and use the right factors to decide how well it should rank.
Paywall implementations and their SEO impact
Different technical setups can influence how well a site with a paywall performs in search rankings. Here’s a rundown of various implementations and how they might affect a site’s visibility in search results:
Structured Data
- isAccessibleForFree
First, you have to make sure Google knows when an article is behind a paywall so it won’t confuse your paywall with something sneaky like cloaking.
You do this by using structured data for news articles. When you set up the structured data for an article that’s behind a paywall, you have to specify that it’s not free. You do this by setting the “isAccessibleForFree” attribute to “false,” which tells Google that the article is either fully or partially paywalled.
Usually, news publishers mix both free and paid content. The value of the “isAccessibleForFree” item is a boolean so if the content is for free the value should be “TRUE” and if the content is paid – “FALSE
- hasPart
By putting the “hasPart” item into your NewsArticle structured data, you can show where the paywall begins. You do this with the “cssSelector” attribute, which should have the CSS class from your article page that marks where the paywalled content starts.
NOTE: "hasPart" is not a required, it's just recommended.
Googlebot verification
By verification of Google and their crawler, Google will be able to crawl and index your content, including the paywalled sections. There are a couple of option to verify and differentiate Googlebot and a regular user.
-
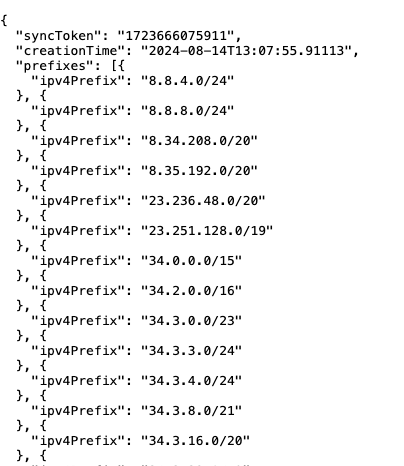
- IP verification – Fortunately, Google provides a JSON with the IP addresses it uses to search the internet. This makes it easy and safe to check if a visitor is actually Google and decide what kind of content to show them on the website.
- I developed a Googlebot IP Verification tool, where you can check a single IP if it's a Google's one or another crawler.
- User-Agent Paywall – When you have a paywall that checks the type of browser, your website shows different things to regular visitors and to Google. Normal visitors see a version of the website that asks for payment to access content, without any free parts. But when Google’s web crawler visits, it sees a version with the full article and all the detailed information it needs to list the article in search results.
The downside of this is that the content won’t be protected on 100% from scrapers because the User-Agent is easy to be manipulated. - JavaScript Paywall – This method verifies the user on client-side (in the browser) by JavaScript. The webpage HTML document contains the full article, and based on where is coming the request the JS can hide the paid content and show the barrier. Googlebot is crawling all pages first without executing the JS and is parsing only the HTML document, that’s why with good server-side rendering(SSR) this won’t be an issue for news publishers. The benefit of this is the flexibility that the JS provides to optimise for conversion but at the same time by just disabling the JS in the browser the content will be accessible.
The downside of this Googlebot verification is that the content still isn’t fully protected. By disabling JavaScript (JS) in a browser or crawler, the content can be accessed for free.
Based on my experience the best way and the most secure is by cross-checking the user-agent and the IP of the request. If the publisher is more conversion-oriented oriented I would suggest a JavaScript paywall because of the flexibility.
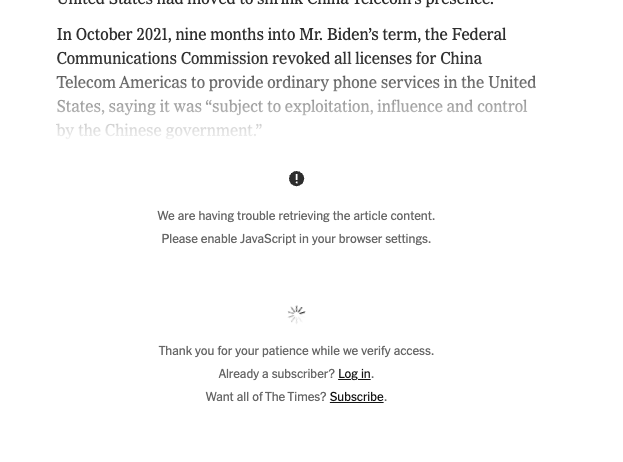
At the same time, monitor sessions where JavaScript (JS) is disabled. If these sessions increase, appropriate actions should be taken, similar to what The New York Times has done. In my opinion, The New York Times implemented a smart solution to prevent access for sessions without JavaScript enabled.
No Archive tag
Search engines like Google might save a copy of your web pages. This saved version is called a “cached” page. Google can show a link to this cached page in its search results, which allows people to see the content of the page even if the original page is not available anymore.
If you don’t want Google to save and show a cached copy of your pages, you need to tell Google not to do this. You can do this by setting a rule on your website. If you don’t set this rule, Google might save a copy of your page and people could find and view this saved version by clicking on the “Cached” link in Google’s search results. This means that even if you have a paywall or special content that you only want paying users to see, they might still see it for free through the cached link.
HTTP header
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
(…)
X-Robots-Tag: noarchive
(…)
Robots tag
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex">
(…)
</head>
<body>
(…)
</body>
</html>
NOTE: In October 2024 Google removed "noarchive" meta tag from their documentation and the "cache:" search operator.
SEO Debugging for Paywalls and Subscription-Based Content
Google’s Rich Results Test(RRT) has been upgraded to show you the validation of structured data for paywalled content. From October 2023 the tool shows if that site is using the proper structured data for paywalled content or not.
- Structured data debugging - you can submit a URL and to check if your structured data is correctly implemented. If you have "isAccessibleForFree" you should be able to see
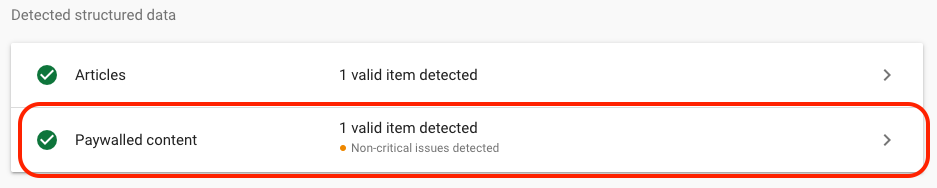
- Paywall barrier debugging - RRT is providing a screenshot of the article which previously was way smaller than now but Google has expanded in the past. If the paywall and the Googlebot verification is implemented well, you should be able to see the page without any paywall barriers.
NOTE: If you are using User-Agent verification I would recommend to add also the Googlebot user agent Google-InspectionTool
What are the potential downsides of setting up a paywall?
Different (poor) user behavior
User experience is a ranking factor and I believe that part of this is how often users click on the “Back” button and return to the search results page (SERP) after visiting a site. If users frequently go back to SERP quickly, it’s a bad sign for the site, suggesting the content didn’t meet their needs.
Websites with high ‘return to SERP’ rates might rank lower on Google over time. Google aims to provide the best search results, and sites that users quickly leave don’t fit the bill.
The real SEO challenge with paywalls is that they can increase ‘return to SERP’ instances, leading to less visibility on Google.
To counter this, publishers can use ‘First Click Free’ tactics or wisely set paywall limits for users from Google, letting them read full articles and reducing ‘return to SERP’ events to avoid long-term SEO harm from paywalls.
Lower CTR than the average
During the NESS conference in 2022, SEO experts from The Times reported a decrease in click-through rates (CTR) as users became aware that the website’s content was behind a paywall, leading them to avoid clicking on the search results.
Based on my experience with paywall content the proportion between free content and paid content should monitored and it’s a good option {again} to implement “First Click Free” which will minimise this routing of the users.
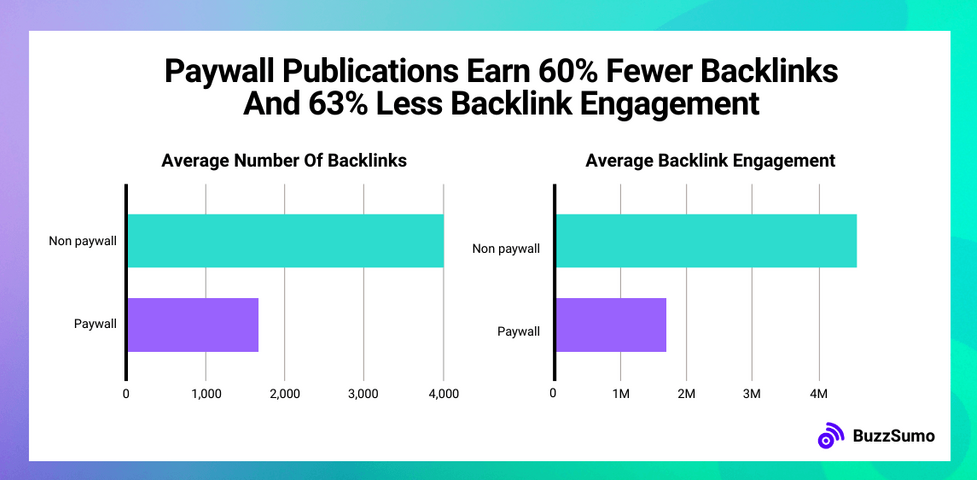
Fewer backlinks
Websites operating behind paywalls often experience a reduction in backlinks because their content is inaccessible to a wide audience. This observation aligns with the findings presented in BuzzSumo’s case study, “We Analyzed Millions Of Publisher Links. Here’s How To Syndicate Your Content & PR For Free” which provides insights into effective strategies for content syndication and public relations without incurring costs.
My opinion as a tech SEO expert
Paywalls are becoming more popular but at the same time more complicated. They can help make publishers monetise their content but at the same time the implementation should follow the SEO requirements and to be based on the user experience and behavior and avoid any damage.
I would recommend the following implementation:
- Use Machine Learning to make your paywall as smart as possible and serve the barrier only on your best users
- Analyse the conversion after the implementation and remove the paywall on the channels that are not performing that well. (i.e. Google Discover)